
Assessing Re-identification Risk from Veteran Status in HIPAA Expert Determination
Introduction
Veterans in the United States shouldn’t have to worry about the privacy of their health data. Between data breaches of the Veterans Health Administration and CPAP Medical Supplies and Services Inc., data from nearly 100,000 veterans has been compromised in recent years. On top of that, commercially available veteran mailing lists make veterans’ personal information more accessible than that of the general public. This means that when healthcare organizations de-identify protected health information under HIPAA, they must take extra care with data that could reveal a patient’s veteran status.
While veteran status is not typically present in healthcare data as an explicit field, it can often be inferred from other values such as clinical codes, payer information, and facility names. As a result, an attacker could infer whether a patient is a veteran which, in turn, increases the risk of re-identification.
A straightforward approach to manage this risk is to remove or redact all indicators of veteran status. In practice, however, this is not always feasible. Some analyses rely on these fields and cannot be conducted without unrestricted access to this information. In addition, it is not always possible to reliably identify all indicators of veteran status, particularly those embedded in semi-structured or free-text fields.
Importantly, not all individuals with veteran status present the same level of risk. Many combinations of demographics are shared by sufficiently large populations that the risk of re-identification remains low, even when veteran status is considered. By quantifying the re-identification risk on a per patient basis, the risk can be managed using a more nuanced approach, resulting in a higher utility dataset with fewer redactions.
Modeling a Re-identification Attack on Veteran’s Health Data
The primary risk considered here is a linkage attack. In this scenario, records from a de-identified dataset are linked to records in another dataset based on shared knowable characteristics, also called quasi-identifiers. Quasi-identifiers can include a patient’s age, sex, location, race, and many other characteristics. In this attack model, the secondary dataset may contain direct identifiers, such as names and addresses, as is common in commercial or publicly available datasets. This means that if a record in the de-identified health dataset is linked to the secondary dataset, the attacker can then learn the patient’s name or address, meaning the patient has been re-identified.
The likelihood of a correct linkage in these attacks depends on how many individuals share the same combination of quasi-identifiers. When many individuals match a given combination, any linkage is more likely to be incorrect. When few individuals match, the risk of correct re-identification increases.
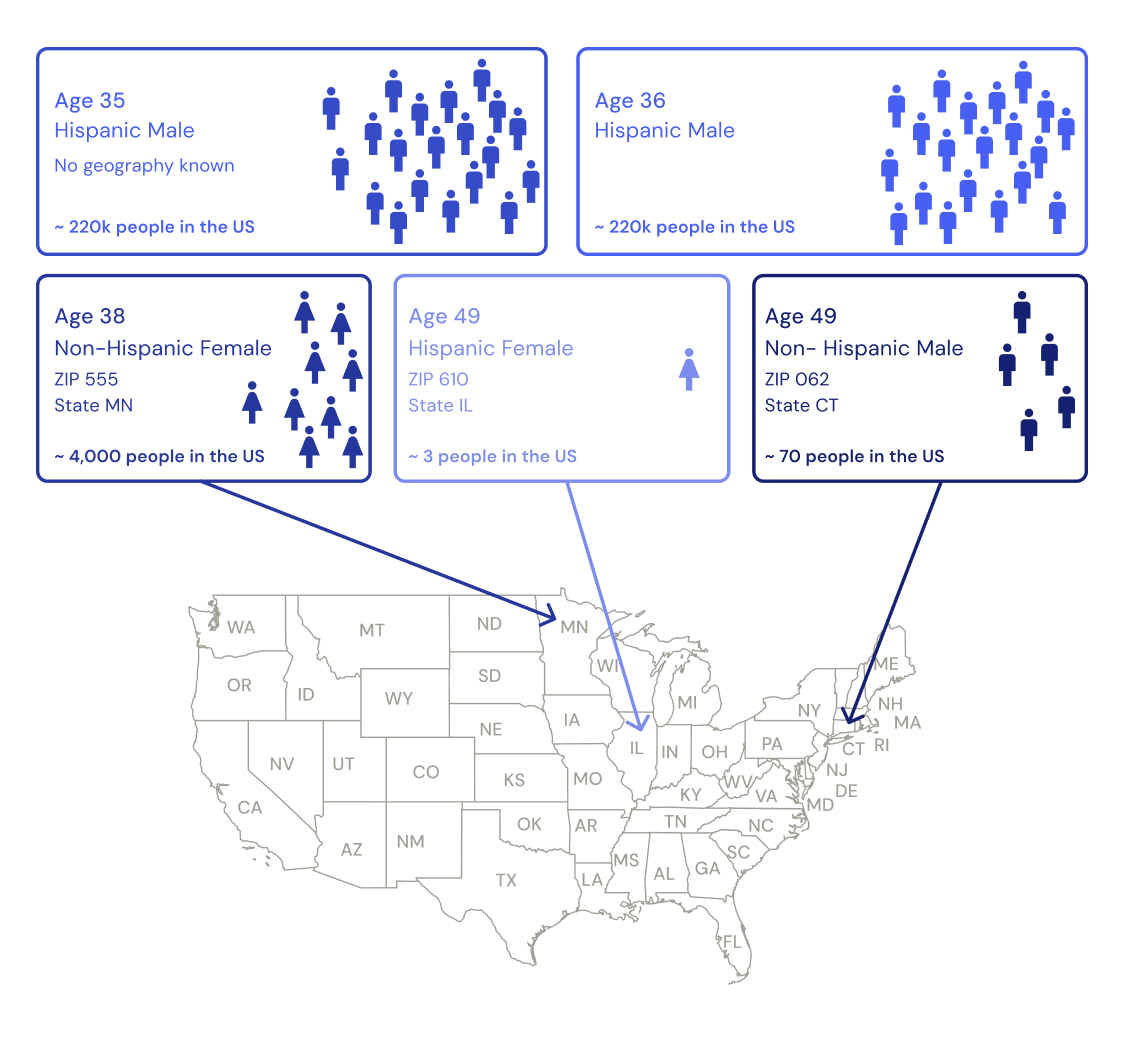
Figure 1: For a health record, quasi-identifiers like the patient’s age, gender, location, and ethnicity can be used to match that record to a person in the real world. However, depending on what combination of these values are known, they may correspond to different numbers of people in the real world. When only partial information is known, such as a 35 year old hispanic male, there may be thousands of individuals that match in the real world. However, when a lot of information is known in less common combinations such as a 49 year old hispanic female living in zip code 610, this may correspond to only a few people. By estimating the number of people in the real world with a combination of quasi-identifiers, the risk of correctly re-identifying a record can be estimated.
Veteran status can function as an additional quasi-identifier. If an attacker can infer or observe veteran status in both datasets, it may reduce the number of matches and increase the likelihood of re-identification.
Veteran Status Indicators
Veteran status is rarely represented as a single, explicit variable in medical data. Instead, it is often inferred from a range of values, including:
- Clinical codes indicating injuries or conditions related to military service (e.g., ICD codes)
- HCPCS Level II codes and procedure modifiers associated with Veterans Affairs (VA) services
- Provider taxonomy codes
- Payer and plan names referencing VA programs
- Facility names associated with VA institutions
- The broader context or source of the data itself
Some of these indicators are structured and well-defined, while others appear in semi-structured or free-text fields. This variability complicates both detection and remediation.
Challenges in Remediation
When veteran status is not required for end use, removing relevant indicators is often the simplest approach. For structured variables such as clinical codes, this can be implemented through methods such as blacklists. This is simple to implement, but for very large datasets the computational cost must be considered.
It is even more challenging when indicators appear in payer names, plan descriptions, facility names, or other semi-structured fields. Identifying all such references reliably is difficult, and attempts to do so can introduce false positives. For example, the abbreviation “VA” may refer either to the Department of Veterans Affairs or to the state of Virginia. Overly broad detection rules may flag non-veteran records for remediation, while overly narrow rules may fail to capture all relevant indicators.
These challenges also exist when veteran status must be retained. In such cases, risk must be mitigated through modification of other quasi-identifiers. Without a way to quantify risk at the individual level, this often leads to conservative approaches that remove or generalize more information than necessary.
Modelling Veteran Population Distributions
In order to assess the risk on an individual level, we can produce estimates for the size of each combination of quasi-identifiers using data provided by the American Community Survey (ACS).
The ACS includes estimates of the veteran population by state, age group, sex, and race or ethnicity. Age is reported in broad groups (e.g., 18–34, 35–54, 55–64, 65–74, 75+).
Even at this level of aggregation, there are combinations for which the estimated population is very small or zero. For example, certain race, age, and state combinations may have no recorded veterans. In other cases, the population is large enough that even relatively granular combinations of quasi-identifiers could still correspond to many individuals.
Because the ACS data is aggregated into age groups, it must be interpolated to support more granular risk estimation. This requires approximating a continuous age distribution within each demographic group. The modelling is performed using splines, separately for each combination of state and race. To extend the estimates to the ZIP3 level, it is assumed that, within a given state and race group, veterans are distributed geographically in the same way as the general population of that race. This allows the model to estimate with precision, for each combination of ZIP3, age, sex, and race, the proportion of individuals who are veterans.
Quantifying Risk in Practice
Re-identification risk can then be evaluated by estimating how many individuals share a given set of quasi-identifiers. Census data provides baseline population counts for combinations of ZIP3, age, sex, and race. These counts can be combined with the estimated proportion of veterans to determine how many individuals with those characteristics are likely to be veterans.
This approach can also be extended to include additional quasi-identifiers, such as marital status or year of death. In doing so, it is implicitly assumed that these variables are independent of veteran status, or that any dependencies are not readily exploitable by an attacker. This is a simplifying assumption, and while it may not hold exactly in all cases, it reflects the absence of detailed public data describing these relationships.
In practice, higher risk is often observed among younger veterans, where the veteran population is smaller. Older individuals, particularly those over 90, are also at higher risk, although this is true regardless of veteran status. By contrast, veterans in their 70s (corresponding to people who were the right age to be drafted into the Vietnam war) are typically in larger populations, and therefore have lower risk of re-identification.
Managing Risk with Targeted Mitigation
A patient-level risk assessment as part of a Datavant Expert Determination makes it possible to ensure a dataset with veteran indicators has a very small risk of re-identification. This method is optimal as:
- Conservative inclusion: Individuals who may be veterans can be treated as such. If the resulting risk is determined to be ‘very small’, no further action may be required.
- Targeted remediation: Remediation efforts can focus on variables that are reliably identified, such as structured clinical codes, while avoiding changes to fields where detection is less certain.
- Alternative mitigation strategies: Instead of removing veteran indicators directly, it may be preferable to modify other quasi-identifiers. For example, generalizing or suppressing marital status may reduce risk more effectively, and with fewer unintended consequences, than attempting to clean free-text fields.
This approach allows more data utility to be preserved, while maintaining compliance with the HIPAA expert determination standard.
Conclusion
Veteran status increases the risk of re-identification when combined with other quasi-identifiers, particularly in the presence of publicly available demographic data. However, the level of risk varies significantly between individuals.
By modelling the distribution of veterans using ACS data and integrating these estimates into population-based risk calculations, it is possible to move beyond uniform or overly conservative remediation strategies. This enables a more targeted approach, in which higher-risk cases are addressed directly, and lower-risk data can be retained with minimal modification.
This approach ensures that the privacy of veterans health data is maintained during de-identification, while preserving as much of the data’s utility as possible.
Contact us to connect with one of our privacy experts to help you perform HIPAA de-identification of health data with veteran status information.
1 HIPAA does not prescribe a fixed threshold for “very small” risk; it is determined by a qualified expert using accepted statistical methods and contextual risk assessment. See The Role of HIPAA De-identification in Enhancing Health Data Connectivity.

