
Referential Data in Datavant Match
How we use referential data to boost identity resolution when matching patient medical records.

Referential data as a source of truth
Datavant recently announced the incorporation of referential data into Datavant Match, an end-to-end, research-grade privacy technology designed to open new use cases within deidentified record matching. Here, we will explore how referential data sets contribute to this new standard for precision and recall in patient matching.
Referential data is exactly what it sounds like: a large body of data to which we can refer in the process of matching, a bridge between otherwise disjointed datasets. Referring to this data allows us to match with very high confidence medical records belonging to a single individual but containing different pieces of personally identifying information (PII). This means that records that would otherwise be difficult or impossible to match using other techniques can successfully be matched. In this respect, referential data acts as a source of truth for our machine learning models.
Datavant’s referential data source of truth is a curated dataset of public records, online data, and proprietary sources assembled with rigorous data hygiene practices covering the entire US population across 30 years. The scope of this data allows us to track changes in personal identifiers for individuals across time, allowing us to make more matches with higher accuracy.
You vs. your data

Despite how fixed you may feel your own identity to be, your personally identifying data is actually a series of isolated snapshots of interactions with the healthcare system. Observed at scale, the PII of a population appears messy and in constant flux. How many addresses have you had? Phone numbers? Ever changed your name? Do you sometimes (but not always) use a nickname or shortening of your name? All of these changes make it more difficult to say with certainty that data in Location A and data in Location B should both be attached to you.
Real world data
To those outside of the healthcare industry, “real world data” may sound like a fixed body of information, but it is neither fixed, nor is it a single, uniform body of data waiting to be opened for exploration. A large variety of players within the healthcare ecosystem hold small slices of the real world data pie. Within several slices is the personal identifying information of any one patient as it was recorded at a specific moment in time, along with some (but likely not all) information about a patient’s health history. Our goal is to connect the latter without exposing the former. This is one of the ways we are working to break down the many data silos across the healthcare ecosystem.
There is enormous value in being able to study real world data, from accelerating pharmaceutical research to monitoring a complete patient journey. But there is little value in trying to study segmented bits of data that we cannot meaningfully connect. With Datavant Match, we can locate individuals’ records across fragmented datasets and know with very high certainty that a set of records belongs to a single patient without compromising patient privacy.
Connecting patient records across data silos
How PII is stored, shared, and linked is regulated by HIPAA. Unlike, for example, a social media platform that can link the identifying data of its users to other platforms and datasets relatively freely (think: targeted ads based on search activity or social posts), our platform must connect data freely enough to be useful across the industry (i.e. to a variety of researchers, healthcare providers, insurance companies, etc.), but also continue to protect the identifying information of patients.
Elsewhere in the Datavant Tech Blog, we’ve discussed some of Datavant’s strategies for connecting the dots of patient data across fragmented datasets, including Datavant’s tokenization, and some approaches for estimating record overlap between datasets. Both of these approaches are part of the larger puzzle that make up our comprehensive matching strategy.
Tokens
Tokens are the first step in how we match patient data while keeping PII secure. A token is an irreversibly hashed and encrypted string based on certain PII elements. Tokens allow for secure storage and exchange of data outside the data owner’s data warehouse. In the case of a security breach with one data owner, the PII contained in other linked datasets remains protected.
A token could be generated off of:

or

For every dataset, we generate many tokens through different combinations of PII. At a basic level, we can make pairwise comparisons between records to determine if they match. We then measure performance by accuracy on pairs of records:
- TP = True positive = correctly predicted match
- FP = False positive = incorrectly predicted match
- FN = False negative = incorrectly predicted non-match
The key metrics we look for are precision and recall.
- Precision = TP/(TP+FP)
- Recall = TP/(TP+FN)
For example:

Record 2 is missing information in the Phone # field and because of that we’re also missing a token that uses Phone # in its definition. Here, 2 token pairings match, 1 token pairing does not, and 1 token pairing is unknowable. There is an upper limit to how certain we can be that these two records match based on comparing these tokens. Better quality tokens would offer more certainty.
Street vs. St.
When you perform Captcha tasks to access websites, you are helping to develop an AI somewhere to perform better at recognizing things humans recognize instantly regardless of the angle at which they are viewed, their relative positioning to other objects, or the way sunlight glances off of them. Similarly, humans recognize common abbreviations of words as equivalent to the word they abbreviate, but a matching algorithm must learn to recognize “Street” and “St.” as equivalent. At the machine learning level, there are many such factors that confound accurate matching, including:
- Formatting inconsistencies: “Main St.” vs. “Main Street” or “1/12/04” vs. “01—12—2004”
- Variations in data content: “Mary” vs. “Maryanne” vs. “M.”
- Changes to identifying data that occur when patients move, marry, divorce, etc.
- Missing data: absence of phone numbers or first names, or any other field of information not deemed relevant at the time of a particular interaction with the healthcare system
- Filler data: using “123—45—6789” in place of a real SSN or “11/22/3333” in place of a DOB
Bad data = bad tokens
Data quality is critical for quality matching. If the above issues are not addressed, then we have large silos full of bad data. But Datavant is not analyzing the original dataset for inconsistencies, missing data, or the presence of filler data; we only analyze the tokenized version of the dataset. Therefore, tokens must be optimized for matching performance. If we see, for example, a single column throughout a dataset with an unusually high frequency of one token, it probably means this token contains some kind of filler data.
We use several other mitigation and standardization processes to address “bad data” issues in token generation. These include phonetic algorithms like Soundex and Metaphone. Soundex was developed in the early 1900’s to better analyze census data. It’s a “sounds-like” algorithm that helps standardize name spelling variations (e.g. “Steven” and “Stephen”). Metaphone is an algorithm designed in 1990 that was intended to be an improvement on Soundex. It takes into consideration the many variations and inconsistencies in English spelling and pronunciation. These and several other standardization and mitigation strategies help “improve” the quality of the data we have available to us.
Below, you can see how these mitigations might play out while generating a set of tokens. Highlighted fields are understood to be accurate. Parenthetical fields have undergone mitigation:

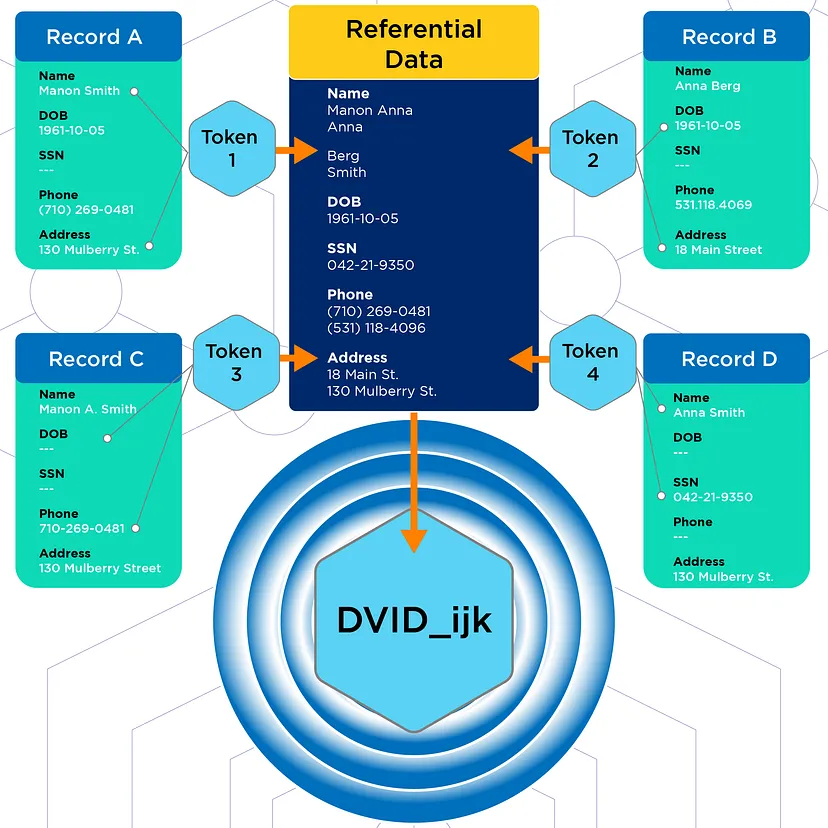
There are several other steps in our machine learning process we won’t go into here. Once we have determined a match, we assign a Datavant ID (DVID) to deidentified patient records. DVIDs are consistent across datasets within a use case-specific, and exist as an appended column within each dataset:

As we mentioned, each dataset captures the data of an individual at a specific point in time, but DVIDs are designed to be stable across time and account for changing addresses, names, phone numbers, and emails.
Training the model
We train our machine learning model on billions of records, looking for patterns between records. Our training data is representative of the US population – drawn from real world data and electronic health record data. This means we see the highest accuracy matches on a very large scale, taking into account the tokens available, their fill rates, and the use case of the data. This allows us to make highly accurate matches regardless of the data provenance or context in which it was collected.
As a result, we have the ability to dial-in the desired balance of precision and recall based on the specific needs of the customer. If we increase the precision of our matching (detect high-confidence matches only), this may come at the cost of recall. If we increase recall (allow the inclusion of lower quality matches), this similarly may come at the cost of precision. With referential data in the mix, these tradeoffs are significantly smaller.
How do we know if we’re getting it right? Referential data as data bridge and source of truth
Finally, in order to verify the success of our machine training, we need to reference our predictions against a source of truth. With regard to the Captcha example given above, human engagement across millions of Captcha interactions help train the AI, and also act as a source of truth for future training. For us, this is where the referential data layer comes in. It allows us to both check our predictions and find additional matches that may have otherwise been missed.
As we mentioned above, precision and recall are often tradeoffs for one another, with higher precision often equating to lower recall and vice versa. By using a referential dataset as a source of truth and bridge among datasets, we are able to boost match accuracy to over 99% precision at 95% recall.
More positive outcomes, fewer negative outcomes
We’re working to boost the positive outcomes afforded by studying well-connected real world data, and we’re also working to reduce the negative consequences of inadequate or poor matching. Missed matches (i.e. your x-ray history not connected to your pharmacy history) limit the possibility for gathering information on patients with chronic conditions. This could result in duplicate tests, missed diagnoses and delayed care. False positive matches (i.e. connecting your x-ray history to somebody else’s pharmacy history) result in inaccurate patient tracking and can jeopardize the quality of research studies. Achieving the combination of high precision and high recall afforded by incorporating referential data means we can sacrifice less in the quest for more higher quality matches.

