
The HL7 FHIR Standard and The Datavant Switchboard
How Datavant is building 1st-party EHR connections to work with (and around) the Fast Healthcare Interoperability Resources API while retrieving medical records

Datavant’s mission is to connect the world’s healthcare data to improve patient outcomes. Our platform to fulfill this mission is the Datavant Switchboard, which can be used for both identified and de-identified data. One of our focuses within the realm of identified data is creating 1st-party connections to every health system’s electronic health records (EHRs) to be able to pull medical records directly on demand. Using these connections, the Switchboard will allow for a frictionless exchange of electronic medical records between patients, payors, and providers, enabling use cases ranging from continuity of care to patient requests for medical history and beyond. Eventually, such exchanges will also power value-based care.
Let’s start by reviewing what it actually means to retrieve medical records.
With the right authorization, authentication, and compliance, the identified side of the Datavant Switchboard fulfills requests for identified medical records in (essentially) three ways:
- A human being manually retrieves the records from a hospital’s EHR. Outside of the Datavant network, this largely still occurs via paper and fax machine.
- The Switchboard connects to a 3rd-party service, often an EHR vendor, such as Epic or Athena, to request records through them.
- Via 1st-party connections, the Switchboard directly connects to a health system’s EHR API, summarizes the requested data and sends it to the requester.
The fragmentation of both paper (yes, paper) and electronic health care records is one of the biggest barriers to improved healthcare outcomes on a broad scale. Building a conduit for the efficient exchange of this information is Datavant’s top priority. It is estimated that in 2021, the number of requests fulfilled by the Switchboard was in the tens of millions, and this quantity represents only a fraction of the entire healthcare ecosystem. Efficiency of exchange, then, is vital. 1st-party connections that reduce the number of transfer points between people or across systems are by far the most efficient method of the above three currently employed, and a streamlined system using a broad set of 1st-party connections has the potential to revolutionize healthcare as we know it. With the Identified Switchboard, we have been diligently working to build exactly that. (You can read more about the potential outcomes of such an efficient information exchange here.)
The FHIR Standard
Established in 2012, the HL7 FHIR (Fast Healthcare Interoperability Resources) Standard is a platform specification intended to define how electronic healthcare information can be exchanged between different computer systems regardless of how it might be stored in those systems. Having grown out of previous specifications in development by HL7 since the late 1980s, the intention was to allow the growing body of electronic healthcare information that exists across the entire healthcare process, including clinical and administrative data, to be available securely to those who have a need to access it.
Key to broad adoption of the FHIR Standard is its ease of implementation, its human-readable serialization format, and its adaptability. Here’s an example of some FHIR data. This example data says that a certain patient with ID 591164 had an encounter (FHIR’s term for an interaction with the health system) on Oct 7, 2019. Looks like patient 591164 was born!! Welcome to the world, patient 591164!

To fully realize the potential for interoperability promised by the FHIR Standard, the Identified Switchboard must be capable of summarizing data for any type of request, while gathering data from any implementation of the FHIR specification. That is, the Identified Switchboard must be as adaptable as the specification itself.
Welcome to the world, FHIR Worker!
To build the necessary flexibility within the Identified Switchboard, we have been working on an application we affectionately refer to as “FHIR Worker.” FHIR Worker is the part of the Switchboard that directly facilitates the retrieval of records via 1st-party connections (i.e.: by connecting directly to the EHR API) and the delivery of that information in a layout determined by the requester. Here is a simplified input that includes basic request parameters: patient identifiers, the reason for the request, where to look for the records, and relevant dates of service:

And here is a snip of an example PDF that would be sent back to the requester:
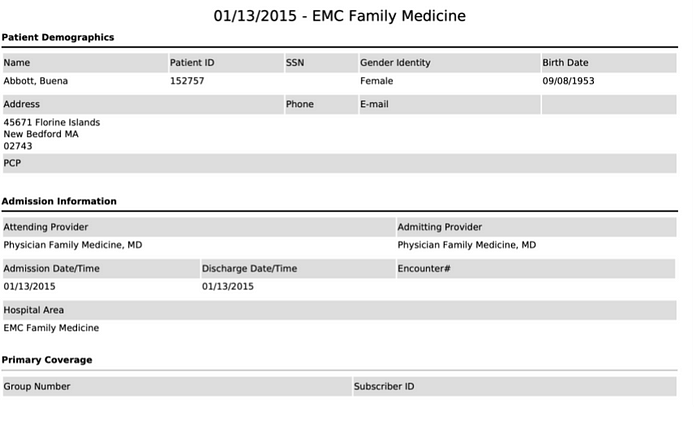
To complete a retrieval, the Switchboard must retrieve many types of data (i.e. FHIR Resources) about the patient. For example, the Patient Resource holds general demographic and descriptive information about the patient: birthdate, name, gender, etc. The DiagnosticReport Resource holds data related to diagnostic tests.
This diagram is a simplified representation of a subset of the data the Switchboard retrieves for a Medicare risk adjustment use case:
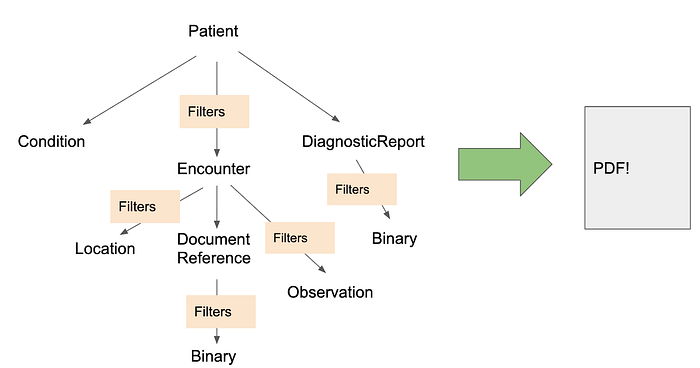
FHIR Worker starts the retrieval for the Switchboard by identifying the patient in the EHR, then uses that patient’s ID within the EHR to get their immunizations, encounters, labs etc. Depending on what data FHIR Worker is trying to pull, it may need to pull some other data first. The arrows in the above diagram show how certain resources are dependent on others during the retrieval process.
An extremely important aspect of this process are the filters. In order to comply with the HIPAA Privacy Rule’s “Minimum Necessary Requirement” clause, which limits unnecessary or inappropriate access to and disclosure of protected health information, FHIR Worker will only retain a subset of the information from the API that is required for the use case. For example, FHIR Worker will only keep encounters within a certain date range that have a status of “complete” (rather than all encounters across all time, including incomplete ones).
Our thesis of flexibility is only proven as we continue to incorporate more data variance.
The problem of variance
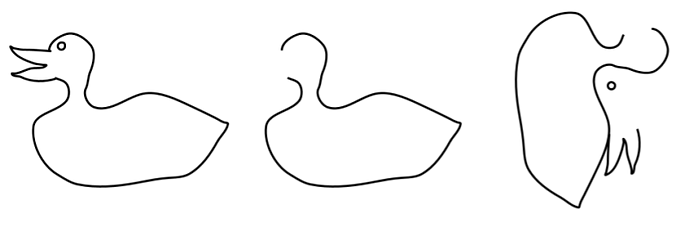
Conforming, optional data, proprietary format
Given that the FHIR Standards are now a decade old, building the FHIR Worker application within the Identified Switchboard might appear to be a relatively straightforward undertaking. However, we learned early on that we cannot make assumptions about data organization, as EHRs exhibit an extraordinary amount of variance in how they make their data available over a health system API. (Remember, part of the reason for wide adoption of the FHIR Standard in the first place was its adaptability.) From an engineering perspective, solving for this variance is one of the most interesting and complex aspects of retrieving data over a wide swath of 1st-party connections via a single application. Because the available data is in fact non-standardized, the Switchboard cannot execute retrievals in a standardized fashion. And again, we are discussing record retrievals currently numbering in the tens of millions of requests from thousands of retrieval locations, and intend to fulfill requests orders of magnitude greater.
The data variance across provider networks goes beyond the adaptability of the FHIR Specification, and includes a number of other factors:
- Even within the prescribed standardization of FHIR, many parts of the FHIR APIs are in fact optional.
- Each EHR system configures access to these FHIR resources separately. Getting access to a FHIR resource in one EHR does not mean that access can be gained to the same resource in a different EHR.
- Not all EHR data is available according to FHIR specs; a lot of it is in proprietary formats. Non-FHIR APIs return data in whatever format the EHR vendor chooses. Additional variation here can also end up being a result of local-level customization regarding how a particular provider would prefer to structure proprietary EHRs.
For reference, here is some data formatted according to the FHIR Specification:

And here is some data that is not formatted according to the FHIR Specification:

There is yet more variance at the health system level of retrieval. The way one health system codes “Radiology” data within their EHR might be different than another, even if both use the same EHR vendor. The retrieval changes across different use cases as well. The data needed for Medicare risk adjustment varies from the data needed for a patient request. Since the manner to retrieve a specific type of data may vary across EHRs as well, we also assume that there is a different retrieval flow for each EHR and use case combination.
Solving for variance with a yoga-master level of flexibility
Even though we have been referring to this application as “FHIR Worker,” its real goal is to allow the Switchboard to interface with literally any EHR API (…eventually, we’ll probably need to rename it.) To deal with potential variance across all possible APIs, and to be able to combine data from records exhibiting different types of variance (i.e.: combine a FHIR Standard record with a proprietary format record), FHIR Worker needs an extraordinary level of flexibility. One solution to this problem could have been to build applications that are configured specifically for individual EHRs and use cases. This approach would put a massive strain on the engineering team, and require a new build every time a new configuration was discovered, which in turn would create recurring bottlenecks in the team’s workflow.
Instead, FHIR Worker takes a configuration-first approach to handling variation, which revolves around the concept of a JSON Resource Definition. The JSON Resource Definition is a configuration that can instruct FHIR Worker to fetch, manipulate, filter, and combine data at a very granular level. By combining these resource definitions together, FHIR Worker can be instructed to retrieve data in an extremely flexible way. The goal of this design is to empower our lay-users to be able to configure the Switchboard to support new EHRs and use cases without significant additional engineering input.
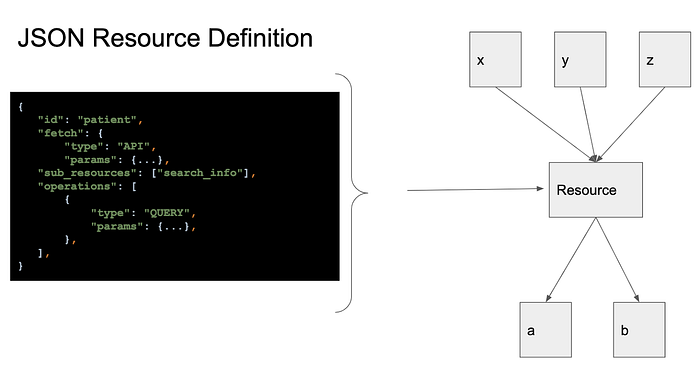
We use Pydantic to define the schema of JSON Resource Definitions. Pydantic validates and parses dicts into Python objects. Since the JSON Resource Definitions can get rather gnarly in their degree of nesting and can also have many attributes, we also use Pydantic to get IDE help and access attributes in a more reliable way than just access keys/elements of dicts directly.
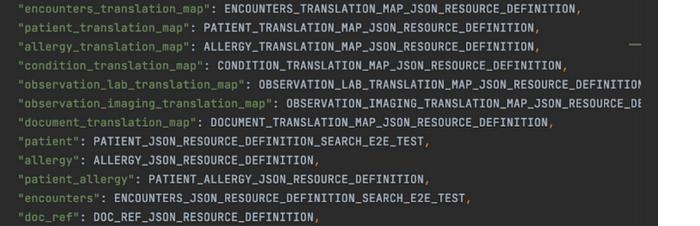
We then put all JSON Resource Definitions into a large map called a Retrieval Definition. This contains all the instructions FHIR Worker needs to evaluate a retrieval.
The Switchboard’s superpower is human connection
The opportunity Datavant has to build these 1st-party connections for EHR retrieval is unparalleled. Following Datavant’s 2021 merger with CIOX, the company is now connected to tens of thousands of providers, each filled with dozens of actual people who are deeply familiar with their own health system’s APIs and data formats. This local-level expertise is vital to our successful building of the Switchboard and the functioning of its internal applications, including FHIR Worker. These folks help us with testing and refinement, and lead us to better understand how we can configure the Switchboard to best fulfill their individual retrieval needs. In essence, it is this massive network of people that allows us to build a single application with many deep and flexible customization possibilities.
Proving our thesis as we build
The Worker Pod (the engineering sub-group building FHIR Worker) has learned to operate under the assumption that there will always be a surprise (in EHRs, in data format, in health systems, etc.), and our thesis of flexibility is only proven as we continue to incorporate more data variance. The success of the Identified Switchboard lies both in its ability to retrieve data in formats that are known to us, but also in its ability to accommodate formats that are currently unknown to us while maintaining the possibility of integrating future unknowns. Meeting the challenge of interfacing with every current (and potential) EHR API is incredibly difficult, but also a major step toward true interoperability within the exchange of health data. The consequences of our success are nothing short of a revolution within healthcare.

Datavant’s Identified Data Worker Pod is:
Victor Cai
Marvo Dolor
Sneha Kalakonda
Aidan Higginbotham
Sherry Liu
Abhishek Goyal
Michael Stensby
The Engineers contributing to the FHIR Worker are:
Lindsey Boivin
Louise Fan
Leon Ho
Akhil Jacob
Victor Cai
Marvo Dolor
Sneha Kalakonda
Aidan Higginbotham
Sherry Liu
Abhishek Goyal
Michael Stensby
Authored by Victor Cai and Nicholas DeMaison.
About the Authors
Victor Cai has a background in data science and machine learning. He has been with Datavant since 2017 where he has been a software engineer and Engineering Manager for the Apps Pod. He is currently the Manager for the Identified Data Worker Pod. Connect with Victor via LinkedIn.
Nicholas DeMaison enjoys telling simple stories about complex things. Connect with Nick via LinkedIn.
Considering joining the team? Check out our careers page and our listing on the 2022 Forbes Top Startup Employers in America. We’re currently hiring remotely across teams and would love to speak with any new potential Datvanters who are nice, smart, and get things done.

