
Max Patton: From Analytics to Architecture
Leveraging Datavant’s support to learn Docker and Kubernetes

Max Patton joined the Product Success Data Ops Team in September 2022. One of Datavant’s core values is prioritizing growth over comfort. Datavant’s Tech Blog writer, Nick DeMaison, spoke with Max about his decision to get out of his comfort zone and learn how to deploy production code. Want to work at a place that actively supports team members directing their own professional growth? Check out our open positions.
Thanks for taking the time to talk, Max. Tell me about your background before joining Datavant.
I studied computational mathematics and had a background in data visualization and reporting. I also did some database administration where I learned the importance of data models, good schemas, and optimizing for reporting versus optimizing for transactional types of work.
One of Datavant’s core values is to prize growth over comfort. You decided to take on a stretch project outside your area of expertise. Tell us about the project. Why did you take it on?
The Engineering Team had a longer-term project that didn’t have a lot of support to deploy code changes on staging and production accounts. This was outside the charter of Data Ops, but because I knew a bit of code and was eager to learn more, they asked me to work on it.
But I’m not a full blown engineer, so I didn’t know how to do this, even though it’s more or less an essential component of computing jobs now. I took it on to prove to myself that I’m capable of committing code changes on the production level for a real codebase.
What kinds of coding had you done previously?
At my previous role at a tofu manufacturer, I committed code to our production environments, but this was at a completely different scale. Most of their production code was internal, so security, logging, and parallelism at the scale that Datavant has was not part of the process. It was comparatively bare-bones in the sense that I did something in Python, updated it, pushed it to the production branch, and then it was out live. It had to pass several automated tests, but it was not nearly as comprehensive as the Github runners Datavant uses.
What did you need to learn for this project for Datavant?
I needed to learn how to deploy, which entailed learning all of the intricacies of our system on the back end, the models we work with and how we represent tables, as well as learning both Docker and Kubernetes.
I was fortunate to have direct support from Engineering Team members who answered a ton of questions. They made themselves completely available to me.
Hold on. What are Docker and Kubernetes?
That question gets to the center of the hardest part of this project: the jargon. Because a more traditional familiarity with IT systems was not in my immediate body of knowledge, I found the jargon to be dense. Dense jargon slows your consumption of content. With more knowledge of networking terminology, I’m sure the content would have been easier to consume.
But to your question, Docker and Kubernetes are complementary tools for managing computational resources. Docker is software that allows you to deploy other software in a nice way. Kubernetes helps with the orchestration of the various components working together.
Give me another example of a jargony concept you had to unpack.
As part of our production pipeline, I had to “apply manifests to Clusters.”
Go on.
Well, that means that I wrote a YAML file…
…YAML?
“Yet Another Markup Language.” It’s a human-readable data serialization language used for writing configuration files. It describes the resources you want to change in the application to fit the code changes you’re making.
Basically, I wrote a command on the command line that says:
kubectl apply -f-
which applies the manifest file that I just wrote to the Cluster. In a sense, you’ve “manifested it into existence”…which I think is like the “magic” bit of computer science that reminds me of its historical proximity to Dungeons and Dragons.
…And a “Cluster?”
It’s a group of computers, probably in the cloud, working together in some way. When it comes down to it, everything we’re talking about so far is in the service of managing resource allocation in the cloud — ensuring that we can do all of the computing we need to do when we need to do it without anything breaking even while we scale our activities. And, just to be clear, the “cloud” is just a bunch of computers sitting in a room somewhere that you rent from somebody to use. Those computers are further partitioned off into more “virtual” computers to run different tasks. Somehow you need to be able to organize all of this (Docker) and manage and allocate the available resources (Kubernetes).
We could visualize it like this:
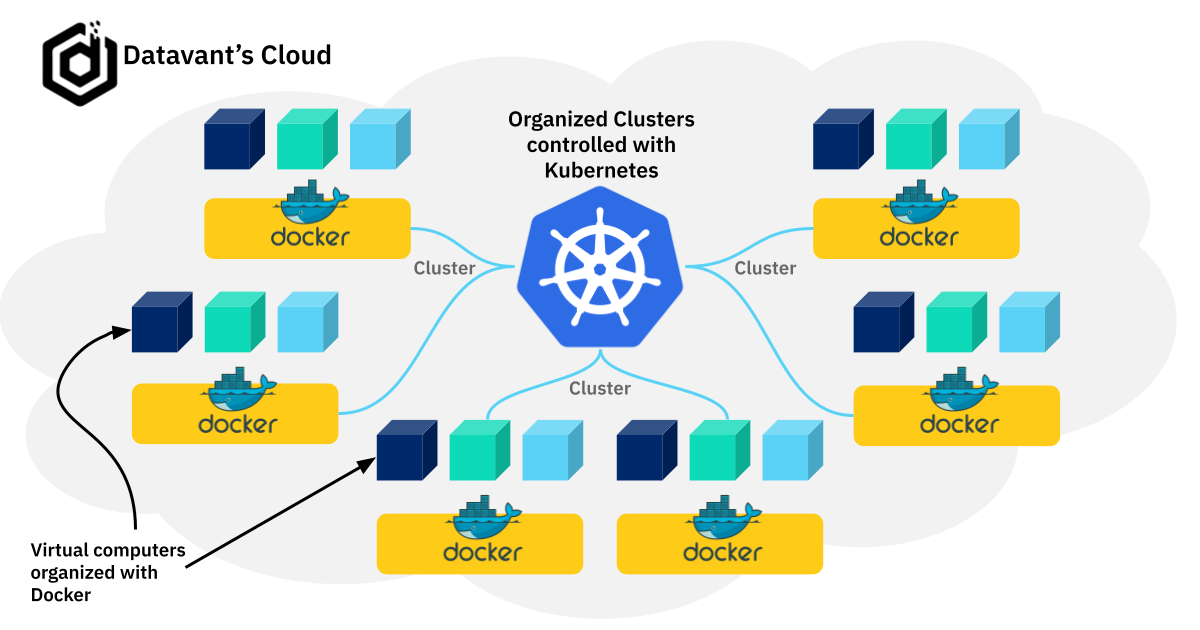
But that’s the most basic overview. If we want to understand the individual components of each Cluster in more detail beyond simply calling them “virtual computers,” then we need to think about more layers within the architecture.
Each Cluster is divided into a Control Plane, containing Master components, and a Data Plane, containing Worker components across our virtual computers:
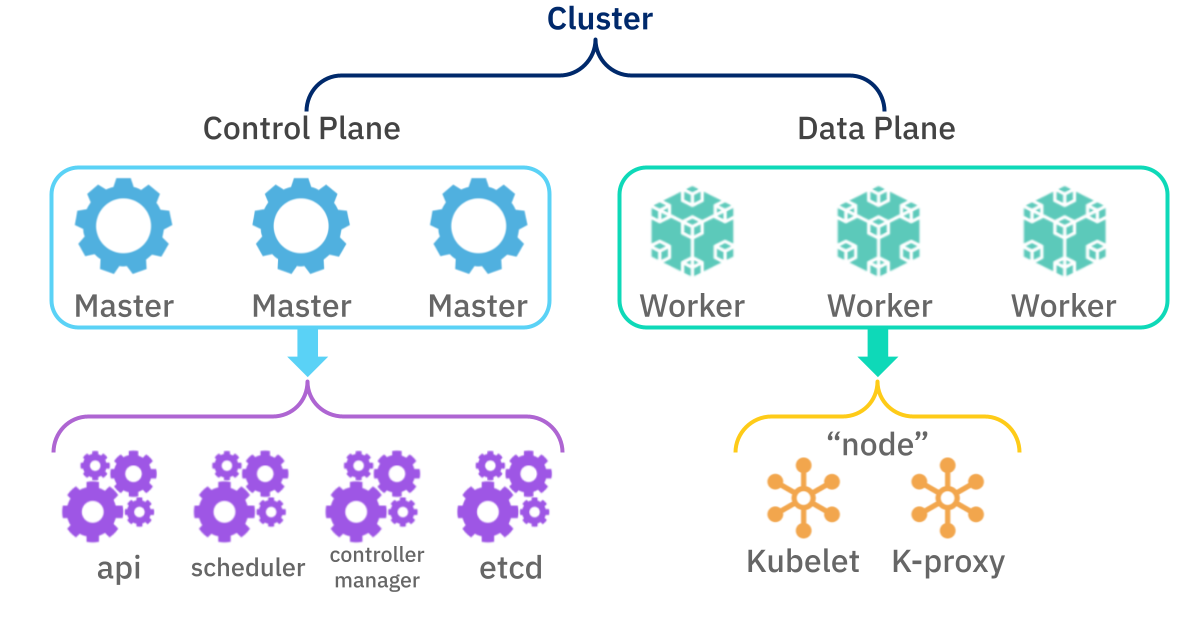
All of this is probably obvious to a software engineer, but even in these two simple diagrams you can see how the meaning of the jargon is not immediately obvious if you’re coming to it from a mathematics and analytics background. But the jargon is critical to your understanding of the system. We haven’t even begun to discuss things like “etcd” (a distributed key-value store that provides a reliable way to store data that needs to be accessed by a Cluster), or Kubelets and K-proxys. It takes time to understand the underlying concepts as well as to build the vocabulary for talking about the concepts.
How did you approach this? What worked best for your learning style?
For me, reading is pretty powerful. I find a good textbook written by a quality author far more useful than anything else. When something is written, the author has gone through the mental exercise of thinking that their work is going to be “set in stone.” A good author tries to make the work future-proof while also allowing it to remain nuanced. For an extremely detailed and jargon-heavy domain, I find it easier to tie together all of these separate concepts that don’t appear immediately applicable to one another if it’s all written down.
I also enrolled myself into a Udacity course on site reliability, with Datavant’s encouragement and sponsorship. The videos were nice supplemental material. And I was fortunate to have direct support from Engineering Team members like Porter and Anjali who answered a ton of questions. They made themselves completely available to me.
The 70–20–10 model is an acknowledgement that an enormous amount of your professional growth will happen on the job. Datavant actively and directly supports that.
How much of this project did you learn on the job at Datavant?
About 90%. I love that Datavant has given me the opportunity to tackle these nebulous concepts that I’ve always been adjacent to but didn’t fully understand.
What’s your next growth project?
There are several educational initiatives going on within engineering. Right now I’m part of a front-end working group focused on Typescript. (Datavant uses a form of Javascript called Typescript.) I have historically shied away from Javascript, but I would like to do more front-end work than I do now while setting up interactive dashboards.
Any big takeaways for readers?
Datavant subscribes to the 70–20–10 model for professional growth (i.e. 70% of your growth happens on the job). This isn’t to say that growing outside of your job doesn’t happen, but it’s an acknowledgement that an enormous amount of your professional growth will happen on the job. Datavant actively and directly supports that. I’m grateful for this and would recommend Datavant as a place for all continuous learners looking to level themselves up.
About the authors
Max Patton has a background in mathematics and data analytics and works on Datavant’s Product Success Data Ops Team. Connect with Max on LinkedIn.
Nicholas DeMaison writes for Datavant where he leads talent branding initiatives. Connect with Nick on LinkedIn.
We’re hiring remotely across teams and love to speak with life-long learners interested to improve patient outcomes by connecting the world’s health data.

