
Patient Privacy in the Age of Large Language Models
Large language models (LLMs), which are a type of artificial intelligence that can interpret and generate human-like text based on the input they receive, offer a potential step change in productivity in healthcare data operations and research. At the same time, their use in health data flows changes the dynamics of traditional privacy analyses and heightens the need for air tight privacy assessments.
Traditional privacy analysis focuses on datasets. Generative LLMs require an additional focus on the role of technology in tandem with the dataset, and the privacy risk from the technology piece is best assessed via model input and outputs, rather than model internals.
This article illustrates the intersection of patient privacy and the development of an application built on large language models, using the example of a text summarization tool.
Background: Large Language Models Carry Both Potential and Risk
Large language models have the potential to enable tremendous efficiency gains. At the same time, such models carry risk, particularly when trained or used on sensitive data. In the healthcare domain, the responsible use of these models requires an approach that incorporates regulatory, ethical, and technological considerations. This article illustrates the end to end process of building a text summarization tool, highlighting elements of both utility and privacy.
Large Language Models Enable New Insights from Unstructured Data
Suppose a research group RG is studying the impact of long COVID. In particular, RG is trying to infer whether there is a causal relationship between a positive COVID test and subsequent behavioral patterns such as depression and fatigue. In order to measure a symptom like fatigue, the researchers use structured lab data to analyze the levels of certain proteins in the blood that are known to cause fatigue (for example, low levels of hemoglobin).
However, there is also a wealth of untapped research value in unstructured data. For example, unstructured physicians’ notes may contain self-reported indications of fatigue, attitudes towards medication adherence, and relationships with caregivers. Previously, RG has found that using such notes requires an infeasible volume of manual review.
On the back of recent advances in large language models (LLMs), RG is planning to build a tool that will reduce manual review. Specifically, RG will build a text summarization tool that will take primary care physicians’ (PCP) notes as input and return a brief summary of the text. The efficiency gains in extracting behavioral information from PCP notes opens up a new category of patient insights with the ultimate goal of informing the development of improved treatments.
RG will be obtaining the PCP notes from a health system HS who is collaborating on the project and whose patients stand to benefit from RG’s insights.
Customized Training Data Augments LLM Performance
We focus on privacy considerations in the context of the text summarization tool that RG is building to summarize the content of PCP notes. In order to build its text summarization tool, RG begins with a pretrained third party summarization tool and customizes it by training it further on the PCP notes from HS. The performance of LLMs that have been pretrained on domain-agnostic data can be improved via additional training on domain-specific data, specifically for a domain such as healthcare with a distinctive lexicon of terminology [1].
De-identifying LLM Training Data Protects Privacy
Rather than send raw patient data, HS de-identifies the data in order to minimize the risk of re-identification in the data they are sending, and comply with HIPAA’s Privacy Rule [2]. De-identifying free text can be a challenge on its own, although natural language processing tools that enable context-aware redaction of sensitive information make this feasible in many cases. These tools, which themselves have been bolstered by the advancements of LLMs, demonstrate that data privacy solutions stand to benefit from the development of AI.
Expert Privacy Analysis Renders LLM Training Data De-identified
Having run its redaction tool, HS now undergoes a HIPAA expert determination [3], in which a privacy expert analyzes the dataset and use case in question. If such an expert determines that there is very small risk of re-identification, the data is considered HIPAA de-identified and able to be shared as intended. In practice, experts typically recommend a series of data modifications that the data originator needs to implement in order to achieve the very small risk threshold.
The use case of data for the purpose of LLM training presents a new set of privacy considerations. Chief among them is the implication of reasonably available information [3]. In general, when evaluating data privacy risk, one must consider whether a dataset is able to be joined to other datasets that are “reasonably available” (for example, in the public domain, or easily purchasable). To take an extreme example, if a custom patient-level identifier in a dataset were also attached to an individual’s phone book listing, then an attacker could easily identify patients in the dataset.
LLMs are warping the notion of what information should be considered reasonably available since they may be trained on an internet’s worth of information. Suppose a dataset contains a field with an anonymous patient identifier coming from a medical record number (MRN) system that is unique to a hospital. A traditional expert determination that evaluates the dataset as a standalone dataset for analysis would likely recommend that the MRN be hashed to minimize the possibility of linkage to the MRN from an unauthorized dataset (the hashed MRN field may be valuable for disambiguating similar but non identical patient records).
The level of risk introduced by such an MRN and the need to hash it is heightened in the context of LLMs. If these MRNs were to exist in any dataset that the LLM has been trained on, which could include the open internet in addition to proprietary datasets, the LLM could in theory connect the MRN from the dataset to other identifying information in the LLM’s training corpus. If the LLM is being used to generate free text (versus, say, perform sentiment classification) and is not designed with appropriate safeguards, this identifying information could be revealed if given a calculated and targeted prompt.
Robust Testing of Model Inputs and Outputs Helps Protect Privacy
The baseline model that RG is working with has been trained on terabytes of data that RG cannot independently evaluate, and the baseline model architecture contains billions of parameters. Therefore, risk stemming from the baseline model is best understood through model inputs and outputs. Specifically, RG can test a variety of model inputs, ranging from standard PCP notes to malicious prompts intended to expose potentially sensitive training data. RG can then evaluate the summary text outputs for PHI by using a combination of human review and NLP tools similar to what HS used to redact PHI from its training data.
With regard to the PCP notes used for model fine tuning, by having de-identified these notes, RG minimizes the risk that its model could be prompted to release PHI from this training data. Note, however, that this risk is non-zero, as in theory, an LLM could be trained on de-identified data that when used in combination with new model input could reveal sensitive information about an individual in the original training data. Therefore, in addition to tests for the baseline model, RG also tests inputs and outputs for the final, fine-tuned model as well.
Privacy is not a one-off consideration. Even in the case of static datasets, when relevant new information enters the public domain, such datasets should be reevaluated for privacy risk stemming from potential new linkages. There are certain maintenance considerations, however, that become particularly pertinent in the context of AI.
RG will have future opportunities to improve its model’s performance by further fine tuning it on new data that it analyzes for its study, going through the aforementioned training process. In this instance, RG would revisit the privacy considerations it evaluated in the course of its initial model development. The intricacies of the architecture of an LLM make it impractical to isolate the “imprint” of any single record of training data across various model versions. Moreover, it is the model input and output that one has control over when using the model. Therefore, RG uses the aforementioned “input/output” approach to assessing model privacy rather than attempting to associate changes in model behavior with individual training data records.
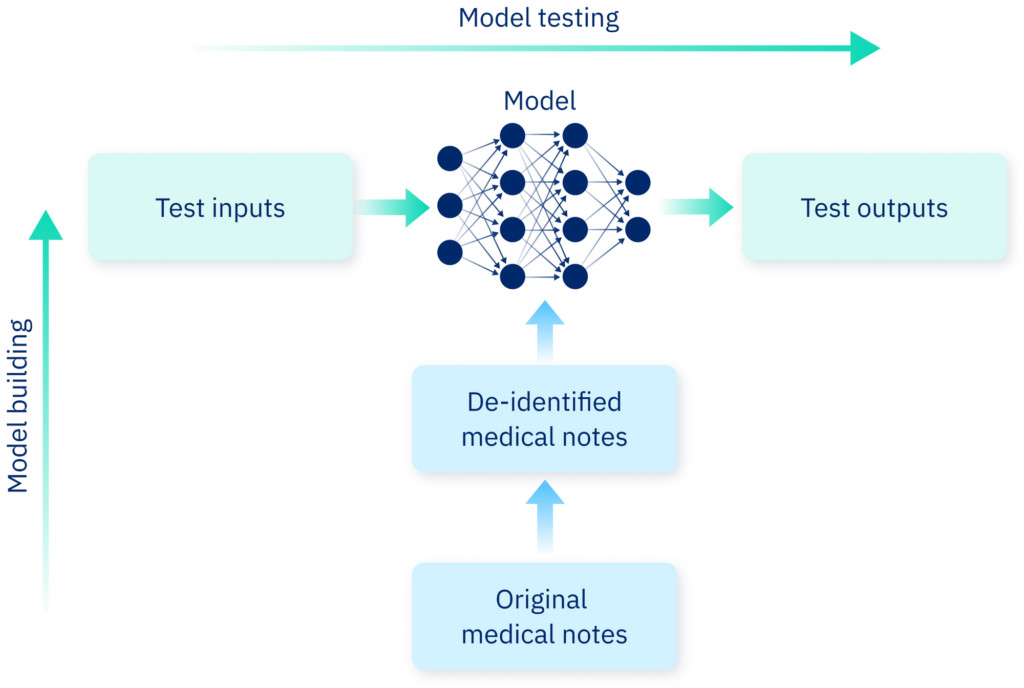
Representation of model building and testing. Along the vertical axis: medical notes are de-identified before being fed to a large language model for training. Along the horizontal axis: The model is tested by inputting a range of possible texts, and evaluating the output.
Training and Evaluating LLMs Requires Both Automated and Manual Processes
To recap, HS has now:
- Made preliminary redactions of PHI from its dataset with the aim of HIPAA de-identification.
- Undergone an expert determination in which a privacy expert evaluates the redacted dataset in question and informs HS of any further measures that HS must take (such as stricter redaction rules) so that the dataset carries very small re-identification risk.
- Implemented any further data modifications from the expert determination.
- Sent the de-identified data to RG for use.
Zooming out, although this process contains a few steps, it can be done within a matter of weeks, is a dramatic improvement from the days of siloed data systems, and unlocks tremendous research utility.
RG is now ready to use the PCP notes to train its text summarization tool. After deciding on a baseline model, RG prepares the data for training. As is the case with the training of any machine learning model, data preprocessing, model choice, and parameter tuning require careful thought and some experimentation.
In this case, labeling of training data amounts to generating gold standard summaries of the PCP notes to be used for training. Such labeling can be achieved via manual review with validation from medical professionals1 or in combination with an existing state of the art model such as GPT-4, which, although potentially costly and in violation of terms of service to run at production scale, could be used in a one-off manner to generate summaries for the training data.
RG also needs an objective means by which to evaluate model performance — that is, how effectively the tool is able summarize PCP notes. RG can measure performance via a combination of subjective manual review and objective computational metrics.2
Equipped with an implementation plan for the appropriate privacy considerations, RG works through the life cycle of machine learning model development, and builds its text summarization tool.
Governance Plays a Critical Role in the Privacy Implications of LLMs
RG should also consider the way governance intersects with privacy in this context. There are existing regulations around the use of healthcare data for research. One might ask whether the training of LLMs for the purpose of healthcare tool development falls under the “research” umbrella in existing regulation; for example, research is a permissible use of a Limited Data Set [4].
Bias has long been a problem in machine learning, and regulation has been springing up to address it in various forms (for example, in hiring practices [5]). In the development of its tool, RG should test the summarization tool for various forms of bias (for example, how the summarization accuracy compares across different ethnic groups), aim to mitigate it, and record the results.
RG must also consider the liability and public perception associated with its model. For example, suppose a physician uses a summary generated by the tool as input into a diagnosis they make that turns out to be incorrect. What type of disclaimers does RG’s tool need to have to protect against unduly burdensome liability? Even if use of the tool is less likely to lead to an incorrect diagnosis than the alternative of manual human summarization, the public and media will likely be less forgiving when the error is made by AI. This dynamic has played out with respect to the disproportionate coverage that car accidents involving self-driving cars receive despite studies suggesting their superior safety [6,7]. In order to gain public trust, RG can internally safeguard access to training data and model training processes, and log and make auditable such access at an individual level.3
Privacy Hub by Datavant
Privacy Hub by Datavant is the leader in privacy preservation of health data, offering independent HIPAA de-identification analyses and Expert Determinations as well as advanced technologies and solutions to improve the quality, speed, and verifiability of the compliance process.
Learn about how Privacy Hub can address all your evolving privacy needs.
Footnote
- Human input into the labeling process can also be integrated directly into the model training process via reinforcement learning with human feedback.
- Manual review is critical to ensure the tool is acting as intended both with regard to summarization quality and general functionality (for example, to ensure the model is not outputting data that is outside the scope of the original text). At the same time, programmatic metrics such as ROUGE enable RG to grade the model across a larger volume of data, which will be important as RG continues to monitor the performance of the model as it is further fine tuned over time and possibly used on new types of data.
- To further engender trust, the details of these internal safeguards, in addition to “input/output” tests, could be made publicly available when doing so does not compromise their integrity. Moreover, RG can build logging mechanisms into its software that record metadata associated with any individual run of the software in practice (of course, there are also privacy implications that must be considered with such logging!).
References
- Luo R, et al. BioGPT: Generative pre-trained transformer for biomedical text generation and mining. Briefings in Bioinformatics. 2022;23(6):bbac409. Available from: https://doi.org/10.1093/bib/bbac409
- U.S. Department of Health & Human Services. HIPAA Privacy Rule [Internet]. Available from: https://www.hhs.gov/hipaa/for-professionals/privacy/index.html
- U.S. Department of Health & Human Services. De-Identification of Protected Health Information [Internet]. Available from: https://www.hhs.gov/hipaa/for-professionals/privacy/special-topics/de-identification/index.html
- U.S. Department of Health & Human Services. Limited Data Set [Internet]. Available from: https://www.hhs.gov/hipaa/for-professionals/special-topics/emergency-preparedness/limited-data-set/index.html
- New York City Council. Int 1696-2019 [Internet]. Available from: https://legistar.council.nyc.gov/LegislationDetail.aspx?ID=4344524&GUID=B051915D-A9AC-451E-81F8-6596032FA3F9
- Teoh ER, Kidd DG. Rage against the machine? Google’s self-driving cars versus human drivers. Journal of Safety Research. 2017;63:57-60. Available from: https://doi.org/10.1016/j.jsr.2017.08.008
- Nees MA. Safer than the average human driver (who is less safe than me)? Examining a popular safety benchmark for self-driving cars. Journal of Safety Research. 2019;69:61-68. Available from: https://doi.org/10.1016/j.jsr.2019.02.002

