
Summer 2021 Intern Spotlight: Distribution and Segmentation Tools with Chris
We had four interns join us at Datavant this summer! In this post, we’ll highlight Chris’ summer internship.
A little about me

Name: Christopher Zou
Course of Study: Computer Science & Molecular and Cellular Biology: Biochemistry at UC Berkeley
Fun Fact: I used to work at Chipotle!
Team: Protect (Identified pod)
Why Datavant
Previously, I’d built computational chemistry software and done a sales internship. What I was looking for in summer 2021 was a formal engineering experience — one where I could learn what it meant to be a good software engineer. I also thought it’d be nice to work in health: I want to help people and my work with Phoenix Consulting Group, one of my clubs at Berkeley, has given me insight into how tech can solve meaningful problems in healthcare.
Coincidentally, Nolan, one of Datavant’s engineers, knows one of my mentors from Phoenix. He sent me an email and I soon learned that Datavant is solving a healthcare problem of enormous scope and importance. Throughout the interview process, I was struck by how open people were about their work and how much ownership they felt when they talked about it. I also liked the way Datavanters could all articulate how they’d grown as engineers and managers because of Datavant’s flat hierarchy. It seemed like a place where I could learn a lot while working on something that mattered.
My project this summer
My project was to implement internal debugging features for Datavant segments and distributions. Segments? Distributions? First, let me give a little bit of context:
At its core, Datavant aims to be the “pipes” through which healthcare data flows. It onboards datasets, removes personally-identifying patient information (PII) and provides them to analytics companies, providers, and other customers.
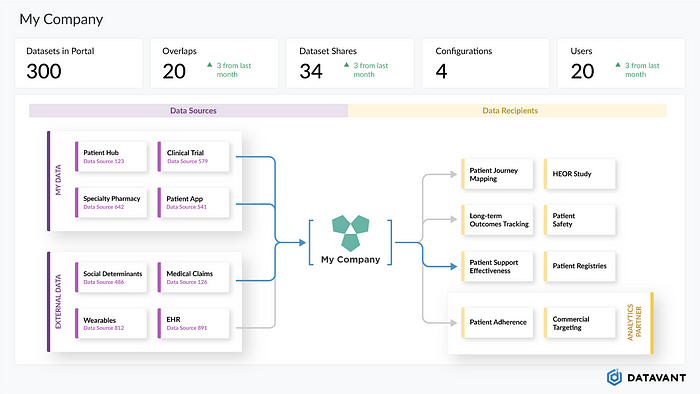
A graphic demo of the Datavant Switchboard, showing how Datavant allows a company to link data from disparate sources (left), tightly control access and sharing of data (right), all while ensuring compliance with record retrieval and privacy-preserving technology.
However, not all customers can use every piece of data. For example, several claims databases distribute their data through Datavant’s cloud software. One of Datavant’s clients wanted to license this data, but only for patients living in California. To accommodate these types of requests, Datavant creates segments: filtered portions of ingested datasets. Also, the originators of these segments are continuously updating their datasets. To keep recipients up to date, Datavant creates distribution subscriptions for each segment and subscribes recipients to them.
From a product quality perspective, it’s important to deliver the correct data or subset of data and do work to ensure the correctness of the data being sent. Prior to this summer, Product Success and Product teams — which create and monitor distribution subscriptions — had three main tools to verify correctness: inspection of the ingested datasets in Datavant’s Snowflake data lake, a “Statistics” button in the internal segment viewer that showed how many records were in the segment, and segment delivery to Datavant’s internal AWS S3 buckets by creating new distribution subscriptions solely for debugging.
This leads us back to my project. As both the number of subscriptions and their complexity grew rapidly, internal users had begun requesting more robust debugging tools. After speaking to product managers Serena and Salma and the protect-identified pod about what would be most helpful, I implemented four features. The first of these was the ability to view segments — not just full datasets — in Snowflake. This allows Datavant users to check the true database-level view of any segment they create in the admin portal and make sure data isn’t malformed or missing.
The second and most time-consuming feature was the ability to preview segment deliveries without creating subscriptions. Distribution previews allow Datavant users to see exactly what the customer will see without having to create a subscription. Along the way, I created endpoints that can be used for further development on segment deliveries without associated subscriptions. Toward the end of the internship, I implemented segment search and subscription metadata-export buttons, features aimed at decreasing time spent working with segments.
A couple of days after I merged the Snowflake views feature, we had an engineering demo day where other engineers had already begun using segment views in Snowflake. It was pretty gratifying to ship features I knew would receive immediate use. This was a firsthand introduction to a big part of Datavant culture: no matter who you are, you’ll be making an impact from day one.
Datavant Create
Every quarter, all of Datavant participates in Datavant Create, or DC. DC is a company hackathon where people from all across the company build out and demo a product from scratch.
With vaccination rates rising and the COVID-19 situation looking stable, Datavant decided to host DC12 in person and fly engineers out for an offsite in SF. Aneesh, one of our co-founders and Head of Engineering, opened the event by inviting people across the company to pitch some 60 project ideas. Some of them had been reprioritized, some of them were moonshots, and some of them were straight-up memes. I also got to pitch an idea of my own. Many of the interns and new grads in my cohort had suffered from inconsistent documentation while onboarding. I wanted to create a company wiki that would act as a single source of truth on bugs, dev setup, and how to work with Datavant services.
I ended up working on my wiki project with Louise and Swarna and a multiparty computation project on a cross-functional team with Victor, Mohak, Gene, Vera, Joe, and Claire. The latter was a proof of concept for Datavant’s patient-facing ambitions, far down the line. Suppose you’re a patient and you want to track down your medical records and visits across your lifetime. Datavant has de-identified data from you from payers and providers. Its Match product can stitch datasets together based on tokens, which are like digital fingerprints generated by one-way hashing personally identifiable information. Suppose you could send Datavant some of the same personally identifiable information. Datavant could create a token and find all your medical records, allowing you to see them and where your data is going. This would return a lot of power over medical data to the patient.
There’s just one problem: in the scenario above, you’d be sending Datavant personally identifiable information. To get around the problem, we implemented a multi-party computation (MPC) solution: an algorithm that allows Datavant and a potential patient to calculate the token together without either party gaining access to sensitive information. We then wrapped the algorithm into Datavant’s frontend framework and presented it to the wider company.

What it’s like to work at Datavant
When I started at Datavant, I had concerns about the remote work environment and about how much they could deliver on their culture promises. Describing a company as a place where people are smart, nice, and get things done sounded more like middle school “life-skills” than defining values for a startup worth the same amount as Discord or Scale. But my conversations throughout the summer showed me that Datavant could just as easily replace smart, nice, and get things done with unbelievably competent, incredibly welcoming, and insanely fast-moving. Simple value definitions belied another value in and of itself: Datavant is a place without fuss.
And no fuss meant that I could sit in on interviews, talk to everyone across every function, and drop time on Travis or Aneesh or other senior leaders’ calendars with a click. The interns and I availed ourselves of opportunities to host virtual lunches and game sessions. Despite a fully remote internship, I felt very plugged in (being remote had also afforded me the opportunity to live in New York City, so who was I to complain?).
Of course, there were tradeoffs: no fuss also meant that there was no company-wide mentorship infrastructure. Expectations could be unclear. Lack of focus on process meant that different product teams could overlap and there was less documentation than friendly for new hires. None of these things are unique to Datavant. In fact, I think they’re issues at a lot of hyper-growth startups. However, the way that Datavant addresses these concerns was encouraging. “More responsibility, fewer rules” — another mainstay of the people team — meant that structured mentorship could exist between mentor-mentee pairs and I could write documentation that immediately helped the next wave of hires.
Overall, I learned a lot about what it meant to be a good software engineer while working on a $100 billion healthcare problem. More than that, I learned how to contribute at a startup, which often meant collaborating with Serena, Salma, Vera, Claire, and other non-engineering colleagues. In the process, I gained friends and mentors who I’m still with touch in today—shoutout to Matt, Porter, Claire C, and many others. I’d call it a summer worth repeating.
Get in touch with Chris via email or visit his personal site.
Join us
Our mission is to connect the world’s health data. If you’re interested in interning or working full-time at Datavant, we’re hiring! Datavant offers a $10,000 referral bonus for any software engineer we bring on board.
Thanks to Matt V., Aneesh, Matt O., and Tommy for reading drafts of this.

